[MySQL] Window Function, date_format

윈도우 함수 (Window Function)
일반적인 GROUP 함수처럼 여러 행을 묶어서 통계(합계, 평균 등)를 내는 기능을 하면서도, 그룹화된 각 행을 ‘그룹 전체 맥락’과 함께 조회할 수 있도록 해주는 기능
window_function(argument) over (partition by 그룹 기준 컬럼 order by 정렬 기준)
#window_function : 기능 명을 사용. (sum, avg 과 같은 기능 명 존재)
#argument : 함수에 따라 작성하거나 생략 가능
#partition by : 그룹을 나누기 위한 기준. group by 절과 유사함
#order by : window function 을 적용할 때 정렬할 컬럼 기준 작성
--------------------------------------------
<집계함수>(<컬럼>)
OVER (
[PARTITION BY <기준 컬럼들>]
[ORDER BY <정렬 기준 컬럼들>]
[프레임 옵션]
)
#PARTITION BY: 어떤 컬럼 기준으로 그룹(파티션)을 나눌지 결정. (없으면 전체가 한 그룹)
#ORDER BY: 순위 함수나 누적합을 계산할 때, 어떤 순으로 연산할지 정함.
#프레임 옵션(ROWS BETWEEN …): 누적합, 이동평균 등을 구현할 때
# “현재 행부터 몇 행 앞뒤까지”를 범위로 삼을지 명시.
그룹화(GROUP BY) vs 윈도우 함수
GROUP BY
일반적으로 GROUP BY와 집계 함수를 사용할 때는,
한 행에 하나의 그룹화된 결과만 남고, 그룹에 속한 개별 행을 다시 조회하기가 어렵다.
즉, GROUP BY로 묶으면 그룹별 ‘대표 정보’(집계값만) 나타나고, 각 행의 세부사항은 사라진다.
윈도우 함수(Window Function)
개별 행과 그룹(혹은 파티션) 전체의 통계를 동시에 볼 수 있다.
#group by
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id;
-- 결과적으로, 부서별 직원 수(부서=1, 50명 / 부서=2, 30명 …)는 알 수 있지만,
-- 직원 개인별 정보(예: 이름, 급여 등)는 이 결과 셋에 나오지 않는다.
#Window Function
SELECT
employee_id,
department_id,
salary,
COUNT(*) OVER(PARTITION BY department_id) AS employee_count_per_dept
FROM employees;
-- employee_id, salary 같은 개별 행 정보가 유지되는 동시에,
-- 같은 부서(department_id) 그룹에 대한 COUNT(*)(즉, 부서별 직원 수)가 한 행에 추가로 표시
-- 이는 GROUP BY만으로는 불가능하거나 매우 복잡한 쿼리가 될 수 있다#예시: 레스트랑별 매출과 음식 타입별 매출을 보여줘
#group by
select a.restaurant_name,
a.cuisine_type,
a.res_sales,
b.cuisine_salse
from(
select restaurant_name,
cuisine_type,
sum(price) as res_sales
from food_orders
group by restaurant_name, cuisine_type
order by 2,1
)a -- 레스토랑 매출
inner join (
select cuisine_type,
sum(price) as cuisine_salse
from food_orders
group by cuisine_type
)b -- 음식 타입별 매출
on a.cuisine_type = b.cuisine_type
------------------------------------------------
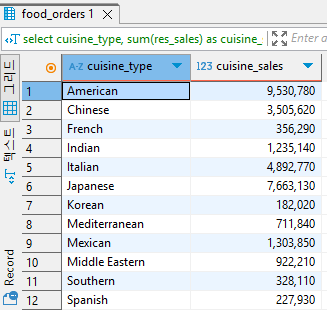
#window function - sum()
select distinct restaurant_name,
cuisine_type,
sum(price) over(partition by restaurant_name order by cuisine_type, restaurant_name) as res_sales,
sum(price) over(partition by cuisine_type) as cuisine_sales
from food_orders
order by 2,1

윈도우 함수를 쓰면 좋은 이유 정리
- 개별 행 정보 + 그룹 통계를 한 번에
- GROUP BY는 그룹화 후 한 행으로 귀결되지만, 윈도우 함수는 “파티션별 집계 결과”를 “개별 행”과 나란히 보여줌.
- 복잡한 계산 로직을 간단히
- 순위(RANK), 이전 행값(LAG), 누적합(SUM OVER) 등 자주 쓰이는 패턴을 짧고 직관적인 문법으로 처리.
- 성능 이점
- 상황에 따라, 서브쿼리나 셀프 조인으로 구현하던 로직보다 윈도우 함수가 더 효율적으로 동작할 수 있음 (DB엔진 최적화).
- 가독성 ↑
- SELECT 문 안에서 직접 “어떤 파티션/순서/프레임을 기준으로 집계”하는지 보이므로, 코드 해석이 쉬움.
정리하면, 윈도우 함수는
- 그룹화된 데이터를 보면서도 개별 행을 유지하고, 순위 매기기/누적합/이전·다음 행 비교 등을 간단히 구현할 수 있게 해주는 SQL 기능
- GROUP BY로는 구현이 복잡하거나 불가능한 통계 요구사항을 쉽게 해결
- 물론 ‘GROUP BY의 대체’가 아니라, ‘새로운 SQL 기능’으로 이해하는 것이 좋습니다.
- 최근 DBMS에서는 윈도우 함수를 적극 권장하거나, 고급 분석 기능(OLAP)을 위해서도 윈도우 함수를 많이 사용한다고 함
RANK()
N 번째까지의 대상을 조회하고 싶을 때 사용
- Rank 는 ‘특정 기준으로 순위를 매겨주는’ 기능
주문 건수별 순위 매기기, 결제 시간이 빠른 순으로 순위 매기기 등이 가능함
#음식 타입별 - 주문 수량이 높은 순서대로 Ranking 매기기
--타입별로 Ranking 3위까지만 조회
select cuisine_type,
restaurant_name,
cnt_order,
ranking
from(
select cuisine_type,
restaurant_name,
cnt_order,
rank() over(partition by cuisine_type order by cnt_order desc) ranking
-- rank() over / 한 쌍으로 사용 / select from 같은 느낌
-- partition by 어떤 단위로 묶을 것인지 지정
-- order by 어떤 값의 어떤 순서로 랭킹을 매길 것인지 랭킹 순서 설정
from(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
)a
)b
where ranking <= 3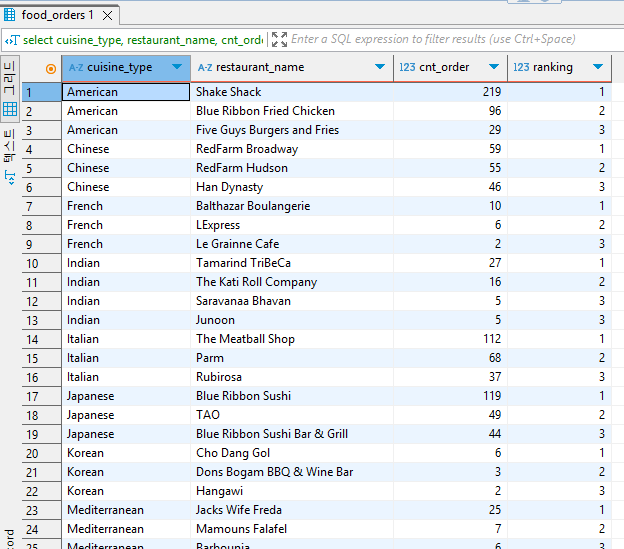
SUM()
전체에서 차지하는 비율, 누적합을 구할 때, sum() 사용
#각 음식점의 주문건이 해당 음식 타입에서 차지하는 비율을 구하고,
#주문건이 낮은 순으로 정렬했을 때 누적 합 구하기
select cuisine_type,
restaurant_name,
cnt_order,
sum(cnt_order) over(partition by cuisine_type) sum_cuisine,
-- cuisine_type별로 cnt_order값의 총합
sum(cnt_order) over(partition by cuisine_type order by cnt_order) cum_cuisine
-- cnt_order값이 낮은 순서대로 cuisine_type별 cnt_order의 누적합
from(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
)a
order by cuisine_type, cnt_order
날짜 데이터
- 년, 월, 일, 시, 분, 초 등의 값
- 목적에 따라 ‘월’, ‘주’, ‘일’ 등으로 포맷을 변경할 수도 있다.
#yyyy-mm-dd 형식 날짜 포맷
select date(column) -- 데이터 포맷을 날짜 포맷으로 지정
from Table Aselect date,
date(date) change_date
from payments
date_format
날짜 데이터를 년, 월, 일, 요일 등 기준으로 볼 수 있다.
- 년 : Y (4자리), y(2자리)
- 월 : M, m
- 일 : d, e
- 요일 : w
select date,
date(date) date_type,
date_format(date(date), '%Y') "년",
-- date 포맷을 date 값의 4자리 년도(y)만 남기겠다.
date_format(date(date), '%y') "년",
-- date 포맷을 date 값의 2자리 년도(y)만 남기겠다.
date_format(date(date), '%M') "월",
-- date 포맷을 date 값의 월(풀네임-영문)만 남기겠다.
date_format(date(date), '%m') "월",
-- date 포맷을 date 값의 월(m)만 남기겠다.
date_format(date(date), '%D') "일",
-- date 포맷을 date 값의 일(서수)만 남기겠다.
date_format(date(date), '%d') "일",
-- date 포맷을 date 값의 일(d)만 남기겠다.
date_format(date(date), '%W') "요일",
-- date 포맷을 date 값의 요일(풀네임)만 남기겠다.
date_format(date(date), '%w') "요일"
-- date 포맷을 date 값의 요일(숫자)만 남기겠다.
from payments
Appendix
group by 사용할 때는 내가 원하는 조건을 명확히 알고 사용해야 한다.
group by 와 window function과 비교하기 위해 sql 작성을 하는 중에cuisine_type 별 price의 합계를 구하는 중이었음
select cuisine_type,
sum(price) as cuisine_sales
from food_orders
group by cuisine_type
------------------------------------
select restaurant_name,
cuisine_type,
res_sales,
sum(res_sales) as cuisine_sales
from(
select restaurant_name,
cuisine_type,
sum(price) as res_sales
from food_orders
group by restaurant_name
order by 2
)a
group by a.cuisine_type
첫 번째는 바로 price 값의 합계를 구하는 방법
두 번째는 restaurant_name별 price 합계를 먼저 구하고, cuisine_type별로 합계 구하는 방법
이론 상으로는 원본 데이터가 같기 때문에 첫 번째와 두 번째의 값은 동일해야 하는데,
실제로는 해보니 차이가 있었음

??? 왜 American 의 값이 서로 다를까?
처음 원본 데이터 확인 부터 다양한 방법을 통해 확인해본 결과
restaurant_name 이름은 동일하지만, cuisine_type이 다른 데이터가 존재하였음

이런 데이터가 있었다는 것을 모르는 상태에서 sum() 을 사용할 때
group by를 restaurant_name으로만 그룹화하여 문제가 발생했던 것!
(실제로 위의 데이터를 보면 Ameriacan 값은 왼쪽 테이블이 크고, Italian 값은 오른쪽 테이블이 크다.)
문제를 확인, group by를 수정한 결과 아래와 같이 동일한 값이 조회되었다.
select cuisine_type,
sum(res_sales) as cuisine_sales
from(
select restaurant_name,
cuisine_type,
sum(price) as res_sales
from food_orders
group by restaurant_name, cuisine_type -- cuisine_type 추가
order by 2
)a
group by a.cuisine_type